Working with big data using Dask
Introduction
Working with large datasets can pose a few challenges - perhaps the most common is memory limitations on the user's machine.
Dask is a flexible, Open-Source library for parallel computing in Python. Dask allows data scientists the ability able to scale analyses from a sample dataset to the full, large-scale dataset with almost no code changes. It's a powerful tool that can revolutionize how you do analytics!
Dask integration on Nebari
Nebari uses Dask Gateway to expose auto-scaling compute clusters automatically configured for the user, and it provides a secure way to managing Dask clusters.
Click here for more information on how this Dask integration works!
Dask consists of 3 main components client, scheduler, and workers.
- The end users interact with the
client. - The
schedulertracks metrics and coordinates workers. - The
workershave the threads/processes that execute computations.
The client interacts with both scheduler (sends instructions) and workers (collects results).
Check out the Dask Gateway documentation for a full explanation.
Step 1 - Setting up Dask Gateway
Let's start by creating a Jupyter notebook. Select an environment from the Select kernel dropdown menu
(located on the top right of your notebook).
warning
Be sure to select an environment which includes Dask
Nebari has set of pre-defined options for configuring the Dask profiles that we have access to. These can be accessed via Dask Gateway options.
from dask_gateway import Gateway
# instantiate dask gateway
gateway = Gateway()
# view the cluster options UI
options = gateway.cluster_options()
options
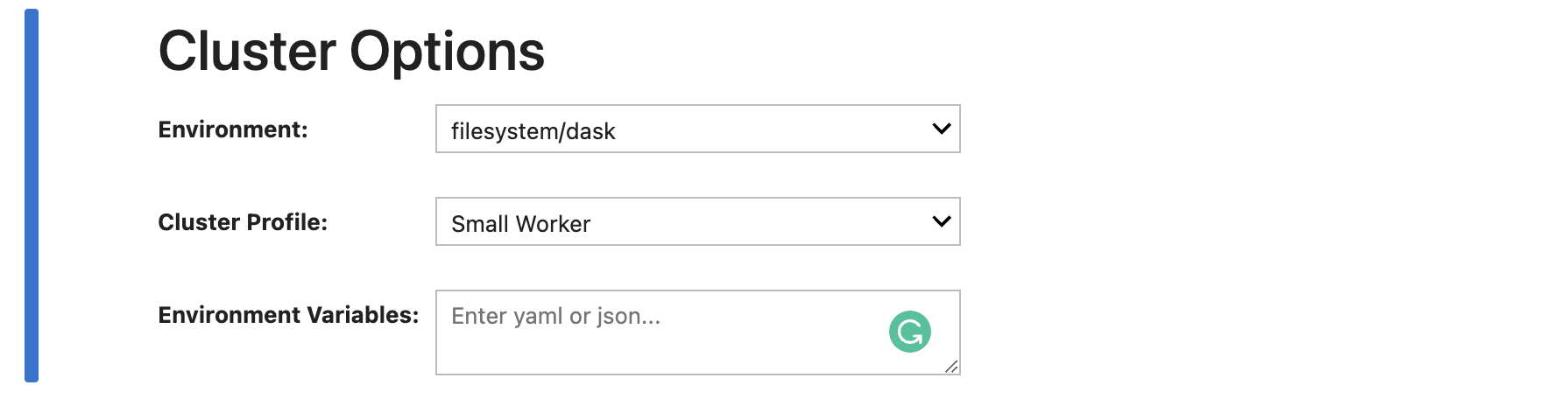
Using the Cluster Options interface, you can specify the conda environment, the instance type, and any additional
environment variables you'll need.
warning
It’s important that the environment used for your notebook matches the Dask worker environment!
The Dask worker environment is specified in your deployment directory under /image/dask-worker/environment.yaml
Step 2 - Creating a Dask cluster
Let's start by creating a new Dask cluster from within your notebook:
# create a new cluster with our options
cluster = gateway.new_cluster(options)
# view the cluster UI
clusterOnce you run the cell, you'll see the following:
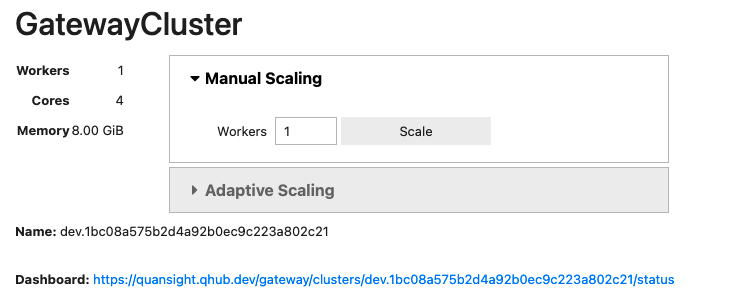
You have the option to choose between
Manual ScalingandAdaptive Scaling.If you know the resources that would be required for the computation, you can select
Manual Scalingand define a number of workers to spin up. These will remain in the cluster until it is shut down.Alternatively, if you aren't sure how many workers you'll need, or if parts of your workflow require more workers than others, you can select
Adaptive Scaling. Dask Gateway will automatically scale the number of workers (spinning up new workers or shutting down unused ones) depending on the computational border.Adaptive Scalingis a safe way to prevent running out of memory, while not burning excess resources.You may also notice a link to the Dask Dashboard in this interface. We'll discuss this in a later section.
Step 3 - Viewing the Dask Client
Once the Dask cluster has been created, you'll be able to get the cluster's information directly from your Jupyter notebook:
# get the client for the cluster
client = cluster.get_client()
# view the client UI
client
On executing the cell, you'll see the following:
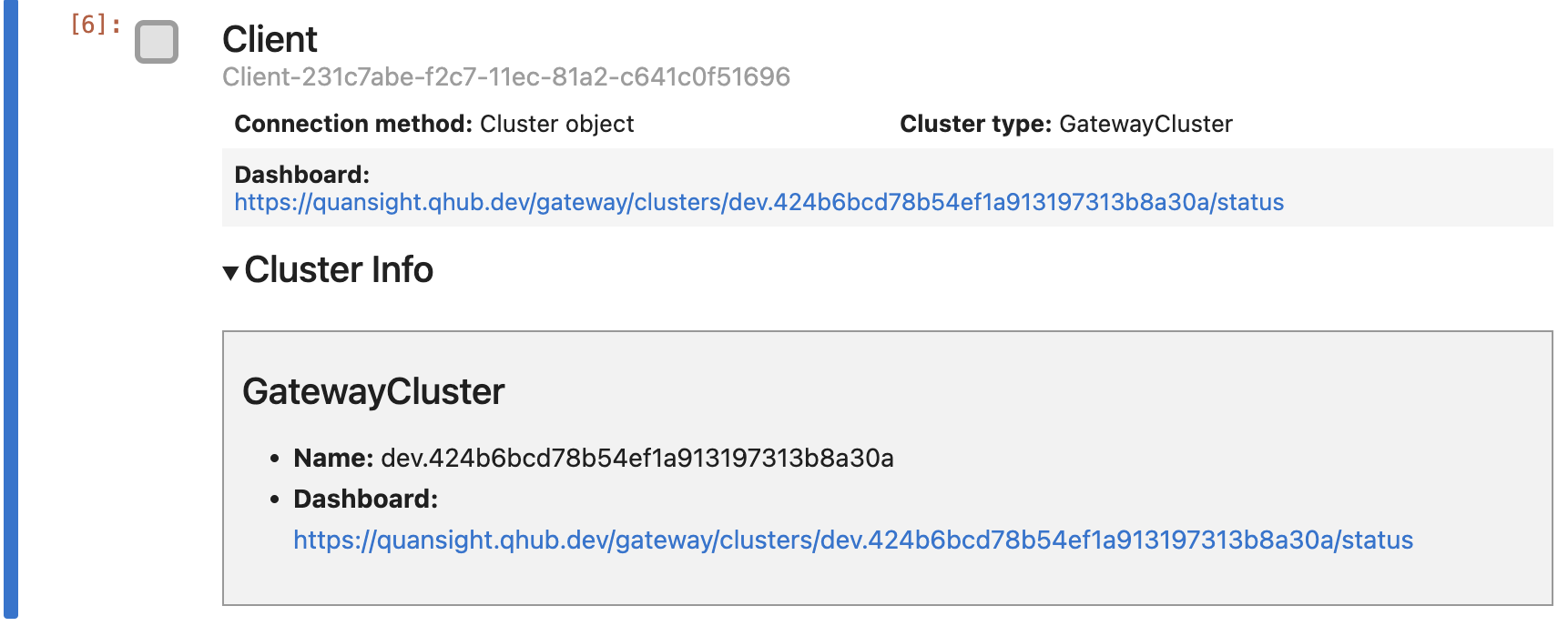
The Dask Client interface gives us a brief summary of everything we've set up so far.
Step 4 - Running your code on Dask
In the following sections, you will perform some basic analysis on the well-known New York City yellow taxi dataset, a subset of which we have copied over to a Google Cloud Storage bucket gs://nebari-public/yellow_taxi_NYC.
note
This dataset is saved in parquet format, a column-oriented file format commonly used for large datasets saved in the cloud.
To get started, we will load the data using a Dask DataFrame. This will lazily load the dataset. Add the following to your notebook:
import dask.dataframe as dd
df = dd.read_parquet(
path='gs://nebari-public/yellow_taxi_NYC/*/*.parquet',
storage_options={'anon':True},
)From here you can start analyzing the data. First, let's check the size of the overall dataset:
dataset_size = df.memory_usage(deep=True).compute().sum()
dataset_sizeOutput:
32426244980This corresponds to 32.43GB of data. Running this one-liner would be impossible on most single machines but running this on a Dask cluster with 4 workers, this can be calculated in under a minute.
Now, let's perform some actual analysis! We can for example, compare the number of taxi rides from before, during and after the COVID-19 pandemic. To do this, you'll need to aggregate the number of rides per day, calculate a 7-day rolling average and then compare these numbers for the same day (April 15th) across three different years, 2019, 2020, and 2022:
# get the pickup date, ignoring pickup time
df["pickup_date"] = df.tpep_pickup_datetime.dt.date.astype(str)
# aggregate rides by pickup date
gb_date = df.groupby(by="pickup_date").agg("count")
# calculate a 7-day rolling average of the number of taxi rides
gb_date["num_rides_7_rolling_ave"] = gb_date.tpep_pickup_datetime.rolling(7).mean()Now you can compare number of taxi rides on April 15th across three different years.
For April 15th, 2019 - pre-pandemic
gb_date.loc["2019-04-15"].num_rides_7_rolling_ave.compute()Output:
pickup_date
2019-04-15 259901.142857
Name: num_rides_7_rolling_ave, dtype: float64or April 15th, 2020 - during the height of the pandemic
gb_date.loc["2020-04-15"].num_rides_7_rolling_ave.compute()Output:
pickup_date
2020-04-15 7161.857143
Name: num_rides_7_rolling_ave, dtype: float64For April 15th, 2022 - post-pandemic
gb_date.loc["2022-04-15"].num_rides_7_rolling_ave.compute()Output:
pickup_date
2022-04-15 119405.142857
Name: num_rides_7_rolling_ave, dtype: float64There were about 260,000 taxi rides a day in middle of April 2019 and that number plummeted to just over 7,100 rides a year later, a full two orders of magnitude fewer riders. Wild!
Performing this kind of analysis on such a large dataset would not be possible without a tool like Dask. On Nebari, Dask comes out-of-the-box ready to help you handle these larger-than-memory (out-of-core) datasets.
The Dask diagnostic UI
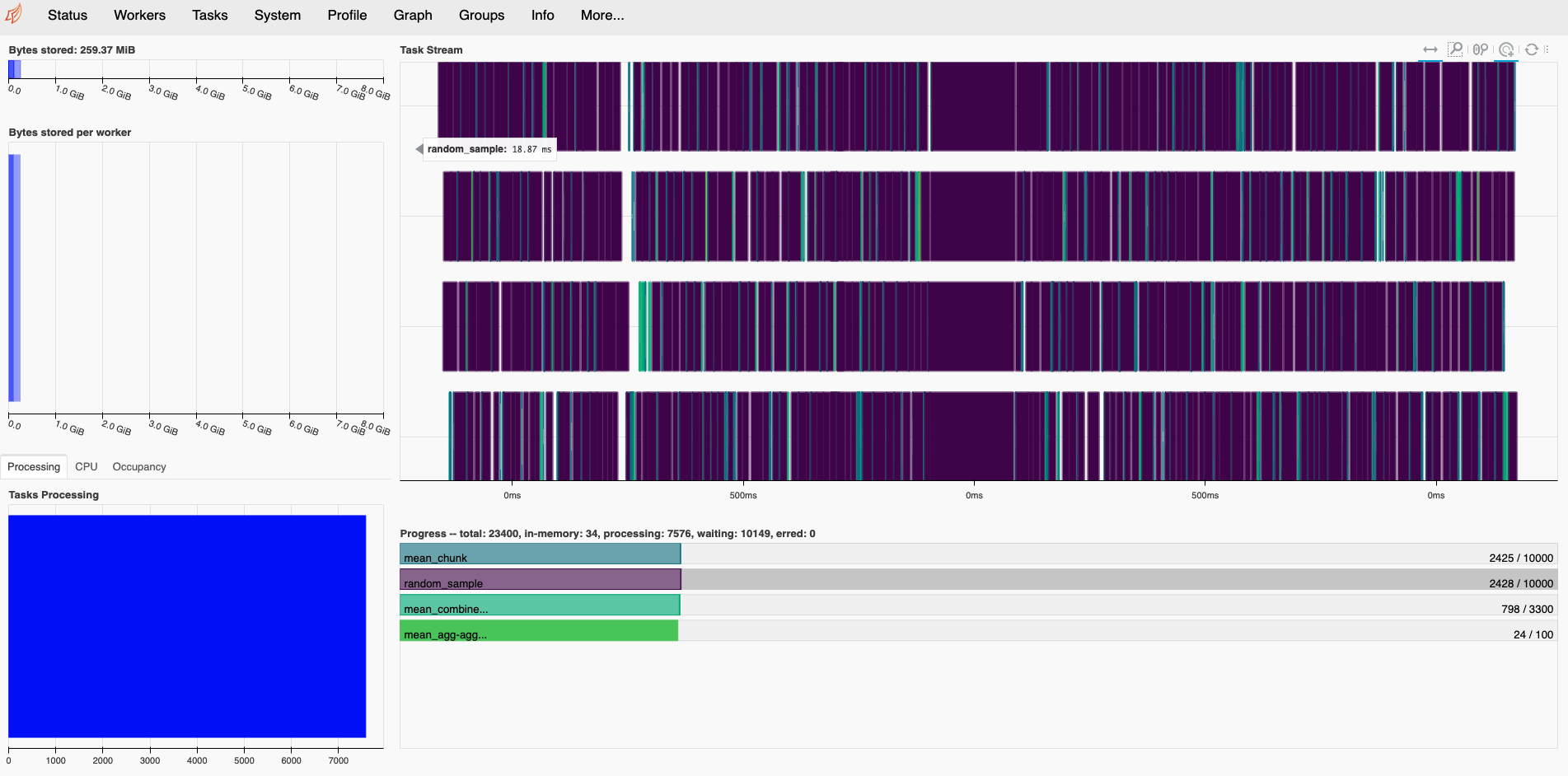
Dask comes with an inbuilt dashboard containing multiple plots and tables containing live information as
the data gets processed. Let's understand the dashboard plots Task Stream and Progress.
The colors and the interpretation would differ based on the computation we choose.
Each of the computation in split into multiple tasks for parallel execution. From the progress bar we see 4 distinct colors associated with different computation. Under task stream (a streaming plot) each row represents a thread and the small rectangles within are the individual tasks.
Check out the Dask Documentation for more information.
Shutting down the cluster
As you you have noticed, you can spin up a lot of compute really quickly using Dask.
warning
With great power comes great responsibility
Remember to shut down your cluster once you are done, otherwise this will be running in the background, and you might incur on unplanned costs. You can do this from your Jupyter notebook:
cluster.close(shutdown=True)
Step 5 - Viewing the dashboard inside of JupyterLab
The Dask-labextension provides a JupyterLab extension to manage Dask clusters, as well as embed Dask's dashboard plots directly into JupyterLab panes. Nebari includes this extension by default, elevating the overall developer experience.
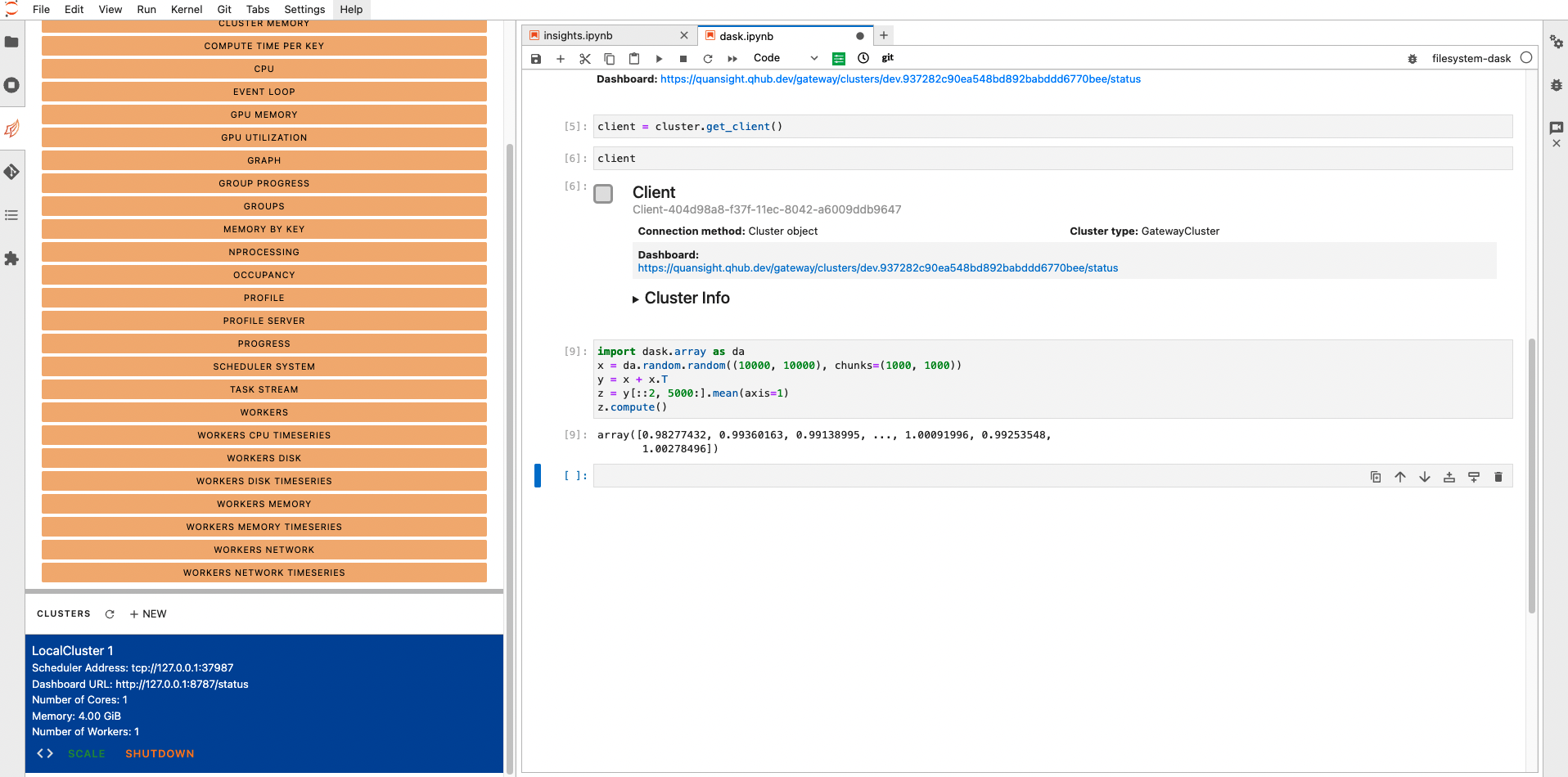
Step 6 - Using Dask safely
If you're anything like us, we've forgotten to shut down our cluster a time or two. Wrapping the dask-gateway tasks in a
context manager is a great practice that ensures the cluster is fully shutdown once the task is complete!
Sample Dask context manager configuration
You can make use of a context manager to help you manager your clusters. It can be written once and included in your codebase. Here is a basic example to get you started (which can then be extended to suit your needs):
import os
import time
import dask.array as da
from contextlib import contextmanager
import dask
from distributed import Client
from dask_gateway import Gateway
@contextmanager
def dask_cluster(n_workers=2, worker_type="Small Worker", conda_env="filesystem/dask"):
try:
gateway = Gateway()
options = gateway.cluster_options()
options.conda_environment = conda_env
options.profile = worker_type
print(f"Gateway: {gateway}")
for key, value in options.items():
print(f"{key} : {value}")
cluster = gateway.new_cluster(options)
client = Client(cluster)
if os.getenv("JUPYTERHUB_SERVICE_PREFIX"):
print(cluster.dashboard_link)
cluster.scale(n_workers)
client.wait_for_workers(1)
yield client
finally:
cluster.close()
client.close()
del client
del cluster
Now you can write your compute tasks inside the context manager and all the setup and teardown will be managed for you:
with dask_cluster() as client:
x = da.random.random((10000, 10000), chunks=(1000, 1000))
y = x + x.T
z = y[::2, 5000:].mean(axis=1)
result = z.compute()
print(client.run(os.getpid))
Kudos, you should now have a working Dask cluster inside Nebari. Now go load up your own big data!